16 KiB
Разведочный анализ (EDA)
Цели разведочного анализа данных
Источник : https://habr.com/ru/companies/otus/articles/752434/
- Понимание структуры и характеристик набора данных
- размер набора данных
- типы переменных
- наличия пропущенных значений
- дубликаты
- Выявление аномалий и выбросов
- Идентификация связей и корреляций между переменными
- Подготовка данных для дальнейших этапов анализа
Инструменты и методы разведочного анализа данных (EDA)
Визуализация данных
Визуализация данных позволяет увидеть и понять паттерны, тренды и взаимосвязи в данных через графику и диаграммы.
Гистограммы и диаграммы рассеяния
Гистограмма – это графическое представление распределения данных по различным интервалам. Она позволяет нам оценить, как часто значения попадают в определенные диапазоны и какие у нас имеются пики или провалы в данных.
Диаграмма рассеяния – это график, в котором каждая точка представляет собой отдельное наблюдение и показывает взаимосвязь между двумя переменными. Это может помочь нам определить, есть ли какая-либо зависимость или корреляция между ними.
- Построение гистограммы
import matplotlib.pyplot as plt
import seaborn as sns
# Генерируем случайные данные
data = [23, 34, 45, 67, 23, 56, 78, 89, 43, 65, 34, 56, 76]
# Построение гистограммы
plt.hist(data, bins=10, color='blue', alpha=0.7)
plt.xlabel('Значения')
plt.ylabel('Частота')
plt.title('Гистограмма данных')
plt.show()
- Построение гистограммы диаграммы рассеяния
import matplotlib.pyplot as plt
import seaborn as sns
# Построение диаграммы рассеяния
x = [1, 2, 3, 4, 5, 6, 7, 8]
y = [15, 25, 30, 40, 50, 60, 70, 80]
plt.scatter(x, y, color='red')
plt.xlabel('Переменная X')
plt.ylabel('Переменная Y')
plt.title('Диаграмма рассеяния')
plt.show()
Ящик с усами (box plot)
Ящик с усами – это визуализация статистических характеристик распределения данных, таких как медиана, квартили и выбросы.
import matplotlib.pyplot as plt
import seaborn as sns
# Генерируем случайные данные
data = [23, 34, 45, 67, 23, 56, 78, 89, 43, 65, 34, 56, 76]
# Построение ящика с усами
plt.boxplot(data)
plt.ylabel('Значения')
plt.title('Box plot')
plt.show()
Тепловые карты (heatmap)
Тепловая карта – это графическое представление матрицы данных, где цветовая шкала показывает степень взаимосвязи между переменными. Это помогает выявить паттерны и зависимости в больших наборах данных.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Генерируем случайные данные
data = np.random.rand(5, 5)
# Построение тепловой карты
sns.heatmap(data, annot=True, cmap='YlGnBu')
plt.title('Тепловая карта')
plt.show()
Сводные статистики и меры центральной тенденции
Сводные статистики и меры центральной тенденции позволяют нам получить обобщенное представление о распределении данных и основных характеристиках. Это ключевые числовые метрики, которые помогают нам понять типичные и наиболее значимые значения в наборе данных.
-
Среднее (Mean): Это сумма всех значений, разделенная на количество значений. Оно представляет общую "среднюю" величину данных.
-
Медиана (Median): Это среднее значение двух средних значений, если количество значений четное, или среднее значение самого центрального числа, если количество значений нечетное. Медиана предоставляет более устойчивую меру центральной тенденции в присутствии выбросов.
-
Мода (Mode): Это значение, которое встречается наиболее часто в наборе данных. Мода может быть полезна для определения наиболее типичного значения.
import numpy as np
from scipy import stats
# Генерируем случайные данные
data = np.random.randint(1, 100, 20)
# Расчет среднего
mean = np.mean(data)
print("Среднее:", mean)
# Расчет медианы
median = np.median(data)
print("Медиана:", median)
# Расчет моды
mode = stats.mode(data)
print("Мода:", mode.mode[0])
Корреляционный анализ
-
Положительная корреляция: Если одна переменная увеличивается, другая также увеличивается. Коэффициент корреляции находится в диапазоне от 0 до 1.
-
Отрицательная корреляция: Если одна переменная увеличивается, другая уменьшается. Коэффициент корреляции находится в диапазоне от 0 до -1.
-
Нулевая корреляция: Отсутствие линейной зависимости между переменными. Коэффициент корреляции близок к 0.
import numpy as np
import matplotlib.pyplot as plt
# Генерируем случайные данные
x = np.array([1, 2, 3, 4, 5, 6])
y = np.array([2, 3, 4, 4, 5, 7])
# Расчет коэффициента корреляции Пирсона
correlation = np.corrcoef(x, y)[0, 1]
print("Коэффициент корреляции:", correlation)
# Визуализация данных
plt.scatter(x, y)
plt.xlabel('Переменная X')
plt.ylabel('Переменная Y')
plt.title('Диаграмма рассеяния и корреляция')
plt.show()
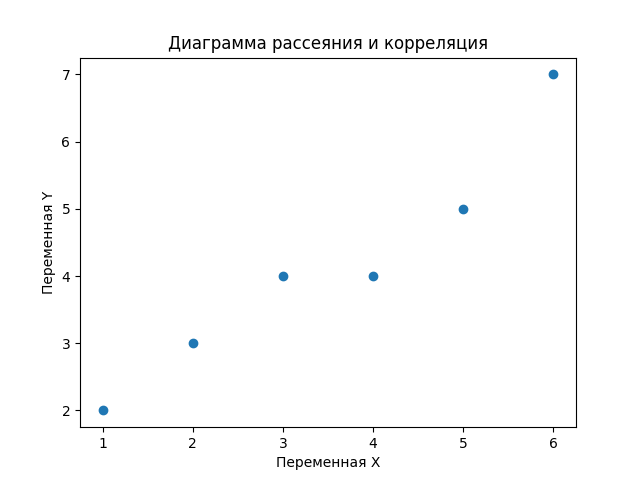
Преобразование данных (например, нормализация или стандартизация)
Преобразование данных – это процесс изменения шкалы или распределения переменных, чтобы сделать их более подходящими для анализа или моделирования. Это важный этап EDA, который помогает сгладить различия между переменными и создать более устойчивые и интерпретируемые данные. Преобразование данных может быть особенно полезным, когда у нас есть переменные с разными диапазонами значений, что может затруднять интерпретацию результатов. Это также может помочь алгоритмам машинного обучения работать более эффективно, так как они часто ожидают, что переменные будут иметь определенный масштаб или распределение.
-
Нормализация (Normalization): Этот метод масштабирует значения переменных так, чтобы они находились в диапазоне от 0 до 1. Это особенно полезно, когда у нас есть переменные с разными единицами измерения и масштабами.
-
Стандартизация (Standardization): Этот метод преобразует значения переменных так, чтобы их среднее было равно 0, а стандартное отклонение – 1. Он делает распределение более "стандартным" и симметричным.
import numpy as np
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# Генерируем случайные данные
data = np.array([[1, 2],
[2, 3],
[3, 4],
[4, 5]])
# Нормализация данных
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(data)
print("Нормализованные данные:")
print(normalized_data)
# Стандартизация данных
scaler = StandardScaler()
standardized_data = scaler.fit_transform(data)
print("Стандартизованные данные:")
print(standardized_data)
Анализ выбросов и аномалий
Анализ выбросов и аномалий – это процесс выявления и исследования значений данных, которые существенно отличаются от остальных наблюдений. Выбросы и аномалии могут возникнуть из-за ошибок в данных, случайных событий или указывать на особенности исследуемого явления.
Основные шаги анализа выбросов и аномалий:
-
Визуализация данных: Используйте графики, такие как ящик с усами (box plot) или диаграммы рассеяния, чтобы визуально выявить потенциальные выбросы.
-
Статистический анализ: Используйте статистические методы, чтобы определить, какие значения считаются выбросами на основе критериев, таких как интерквартильный размах или Z-оценка.
-
Принятие решения: Решите, какие действия необходимо предпринять с выбросами, например, удалить их, заменить на другие значения или оставить без изменений.
import numpy as np
import matplotlib.pyplot as plt
# Генерируем случайные данные с выбросами
data = np.array([10, 15, 20, 25, 30, 500])
# Построение ящика с усами
plt.boxplot(data)
plt.ylabel('Значения')
plt.title('Анализ выбросов')
plt.show()
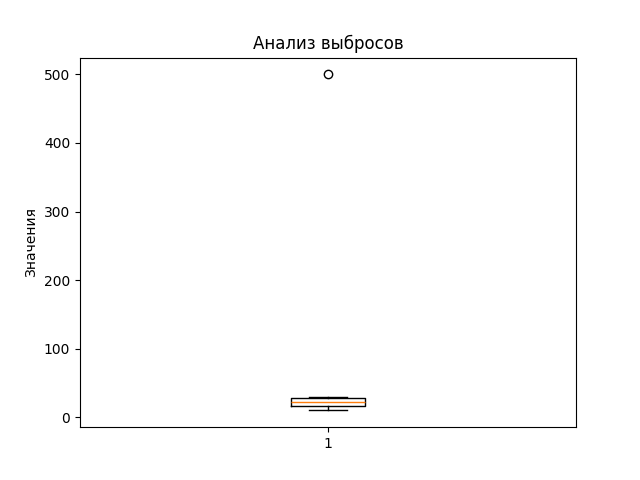
Шаги разведочного анализа данных
Загрузка и первичный осмотр данных
- Pагрузка данных и их первичный осмотр
import pandas as pd # Загрузка данных data = pd.read_csv('sales_data.csv') # Вывод первых 5 строк таблицы print(data.head()) - Обработка пропущенных значений
Задача: Допустим, у нас есть пропущенные значения в столбце Цена. Мы решим эту проблему, заполнив пропущенные значения средней ценой продуктов.
mean_price = data['Цена'].mean() data['Цена'].fillna(mean_price, inplace=True) - Анализ распределения переменных В этом шаге мы будем изучать распределение числовых переменных. Мы построим гистограммы и диаграммы рассеяния для лучшего понимания данных. Задача: Представим, что нам интересно распределение цен на продукты. Давайте построим гистограмму для этой переменной.
import matplotlib.pyplot as plt
plt.hist(data['Цена'], bins=20, color='blue', alpha=0.7)
plt.xlabel('Цена')
plt.ylabel('Частота')
plt.title('Распределение цен на продукты')
plt.show()
- Исследование корреляций между переменными Задача: Допустим, мы хотим понять, существует ли связь между ценой продукта и его количеством продаж. Давайте рассчитаем коэффициент корреляции между этими переменными.
correlation = data['Цена'].corr(data['Количество'])
print("Корреляция между ценой и количеством продаж:", correlation)
- Выявление выбросов и аномалий В этом шаге мы будем искать выбросы и аномалии в данных. Для этого используется визуализация, например, ящик с усами (box plot).
Задача: Давайте определим, есть ли выбросы в столбце Количество (количество продаж продукта). Мы построим ящик с усами для этой переменной.
plt.boxplot(data['Количество'])
plt.ylabel('Количество')
plt.title('Анализ выбросов в количестве продаж')
plt.show()
- Изучение категориальных переменных Задача: Пусть нас интересует, какие продукты являются наиболее популярными среди покупателей. Давайте построим график частоты продаж для каждого продукта.
product_counts = data['Продукт'].value_counts()
product_counts.plot(kind='bar')
plt.xlabel('Продукт')
plt.ylabel('Частота продаж')
plt.title('Частота продаж продуктов')
plt.xticks(rotation=45)
plt.show()
- Визуализация результатов EDA
plt.figure(figsize=(10, 6))
plt.subplot(2, 2, 1)
plt.hist(data['Цена'], bins=20, color='blue', alpha=0.7)
plt.xlabel('Цена')
plt.ylabel('Частота')
plt.title('Распределение цен на продукты')
plt.subplot(2, 2, 2)
plt.scatter(data['Цена'], data['Количество'], color='green')
plt.xlabel('Цена')
plt.ylabel('Количество')
plt.title('Диаграмма рассеяния между ценой и количеством продаж')
plt.subplot(2, 2, 3)
plt.boxplot(data['Количество'])
plt.ylabel('Количество')
plt.title('Анализ выбросов в количестве продаж')
plt.tight_layout()
plt.show()